
2-3 Trees (2-3 Tree क्या है?)
2-3 Tree एक Self-Balancing Search Tree है, जो Data को इस तरह स्टोर करता है, कि Searching, Insertion और Deletion तेज़ और Efficient तरीके से हो सके। ये Binary Search Tree जैसा होता है, लेकिन उसका Improved Version है जहाँ हर Node में 1 या 2 Keys और 2 या 3 Child Pointers हो सकते हैं।
इसे 2-3 Tree इसलिए कहा जाता है, क्योंकि :
- या तो 1 value और 2 branch होती हैं → इसे 2-node कहते हैं
या फिर 2 values और 3 branch होती हैं → इसे 3-node कहते हैं
“2-3 Tree एक self-balancing search tree है, जहाँ हर node में 1 या 2 values और 2 या 3 child हो सकते हैं, और सभी leaf same level पर होते हैं।”
2-3 Tree एक ऐसा Tree है, जिसमें हर Node :
- Sorted Order में Values रखता है
- Balanced Height Maintain करता है
- Efficient Searching को Support करता है
Types of Nodes in a 2-3 Tree
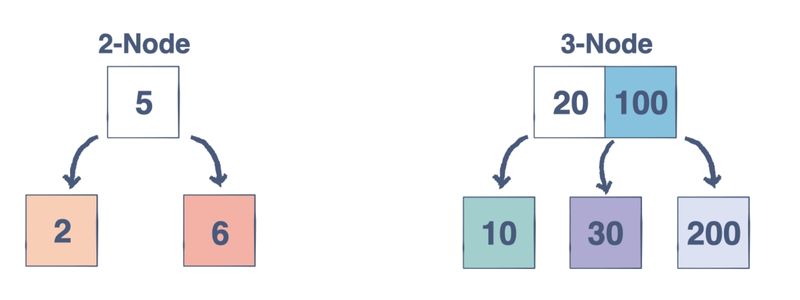
- 2 – Node :
- Contains one data value (key).
- Has exactly two children (left and right) if it’s an internal node, or no children if it’s a leaf.
- Left child < key < Right child.
- 3 – Node :
- Contains two data values (keys).
- Has exactly three children (left, middle, right) if internal, or no children if a leaf.
- Left child < first key < Middle child < second key < Right child.
Characteristics
- Height Balanced : All leaf nodes are at the same depth, crucial for efficiency.
- Search Property : Follows binary search tree principles: values in the left subtree < first key, middle subtree > first key & < second key, right subtree > second key.
- B-Tree Variant : A 2-3 tree is a specific instance of a B-tree with an order of 3 (meaning nodes have up to 3 children).
- Efficiency : Guarantees O(log N) time complexity for search, insertion, and deletion.
Properties of 2-3 tree (मुख्य विशेषताएँ)
Property | Explanation |
Balanced Structure | हर Leaf एक ही Level पर होता है |
Node Capacity | हर Node में 1 या 2 Keys हो सकती हैं |
Sorted Keys | Values हमेशा Increasing Order में रखी जाती हैं |
Fast Searching | Searching Time Complexity = O(log n) |
No Skewness | BST की तरह Left/Right Skewed होने की समस्या नहीं |
Operations
Searching in 2-3 Tree
Algorithm (Step by Step)
Root Node से Start करो
अगर Key Match हो जाए → Success
अगर खोजी गई Value K1 से छोटी है → Left Child में जाओ
अगर K1 और K2 के बीच है → Middle Child में जाओ
अगर K2 से बड़ी है → Right Child में जाओ
अगर Leaf तक पहुँच गए और नहीं मिला → Not Found
Time Complexity
Best Case : O(1)
Average/ Worst Case : O(log n)
Insertion in 2-3 Tree (Insertion कैसे होता है?)
Step-by-Step
सही position वाले leaf तक जाओ
अगर leaf में space है → insert कर दो
अगर जगह नहीं है (Already 3-node) → Node Split
Middle key promote होकर Parent में जाएगा
Deletion in 2-3 Tree (Delete कैसे करें?)
Deletion में 3 Possible केस आते हैं :
| Case | Situation |
|---|---|
| Leaf Delete | आसान है, Value को हटा देते हैं |
| Internal Node Delete | Successor या Predecessor से Replace करते हैं |
| Underflow (कम Value Node) | Merge या Rotation किया जाता है |
Real-Life Applications
Application | Example |
Banking Database | SBI, HDFC Account Records |
Railway Ticketing | IRCTC Live Seat Status |
E-Commerce Logs | Flipkart, Amazon Order Tracking |
Payment Systems | Paytm/UPI Transaction Index |
Telecom | Jio Call Data Management |
Space Research | ISRO Telemetry Logs |
Advantages of 2-3 Tree
1. Always Balanced Structure (हमेशा Balanced रहता है)
- 2-3 Tree की सबसे बड़ी ताकत यह है कि इसका structure कभी भी unbalanced नहीं होता।
- चाहे कितना भी data insert कर दो, tree की height control में रहती है।
2. Fast Searching, Insertion & Deletion
Binary Search Tree में worst case O(n) तक चला जाता है (skewed tree problem),
लेकिन 2-3 Tree में ऐसा नहीं होता।हर operation (Search/Insert/Delete) लगभग समान speed से होता है।
Time Complexity:
Search →
O(log n)Insert →
O(log n)Delete →
O(log n)
3. No Skewed Tree Problem
BST में मान लो sorted data डाल दो (1, 2, 3, 4, 5…), तो वो एक लंबी लाइन बन जाता है।
इसे Right Skewed Tree बोलते हैं, जिससे performance गिर जाती है।
2-3 Tree में ऐसा कभी नहीं होता क्योंकि node भरते ही split होकर balance रखता है।
4. Stable Performance Under Heavy Load
Banking Applications, Online Payments (Paytm/UPI), IRCTC जैसी systems में
जहाँ हजारों searching एक साथ होती हैं, वहाँ stable performance जरूरी है।Node split और balance बने रहने से system slow नहीं पड़ता।
5. Better Data Organization & Sorted Structure
Data हमेशा sorted form में store होता है, जिससे traversal और processing आसान होती है।
Middle key promote होने के कारण tree naturally clean, organized बना रहता है।
6. Ideal For Mid-Size Databases & File Systems
बहुत बड़े डेटाबेस (जैसे Oracle, MySQL internals में mostly B-Tree/B+Tree) यूज़ होते हैं,
लेकिन 2-3 Tree foundation level पर best माना जाता है।File indexing, directory management और small database indexing में perfect fit।
7. Easy Leaf-Level Access
सभी Leaf nodes एक ही level पर होते हैं।
इसका मतलब data तक पहुंचने का distance सबके लिए एक जैसा।
यह property BFS, range searching, database key scan के लिए बहुत useful है।
2-3 Tree Disadvantages (सीमाएँ)
1. Implementation काफी Complex होता है
2-3 Tree को implement करना Binary Search Tree (BST) की तुलना में कहीं ज्यादा कठिन है।
Node Splitting, Merge, Rotation, और Promotion जैसी operations को handle करना beginners के लिए confusing हो सकता है।
2. Memory Consumption ज्यादा होता है
हर node में multiple keys और pointers stored रहते हैं।
2-Node → 2 pointers
3-Node → 3 pointers
इससे memory overhead बढ़ जाता है, खासकर जब millions records हो।
3. Not Suitable for Very Large Databases
डेटाबेस level पर जब billions of records आते हैं, तब 2-3 Tree इतना scalable नहीं रहता।
इसकी जगह B-Tree, B+ Tree, और Red-Black Tree ज्यादा इस्तेमाल होते हैं क्योंकि वो high I/O optimization के लिए design किए गए हैं।
2-3 Tree सिर्फ medium-size data structures में better है।
4. Pointer Management Difficult होता है
जैसे-जैसे nodes split और merge होते हैं, pointers reassign करना पड़ता है।
इससे pointer mismanagement error, dangling pointers, और logical failure का risk बढ़ता है।
Program debugging मुश्किल हो जाता है, खासकर segmentation faults (C/C++ में) आने पर।
5. Hardware Caching-Friendly नहीं है
Modern CPU architecture में cache-friendly memory layouts तेजी से काम करते हैं।
2-3 Tree में nodes scattered होने के कारण cache miss ज्यादा होते हैं।
इससे performance drop हो सकता है, खासकर high-frequency read/write systems में।
6. Insertion & Deletion में Latency बढ़ सकती है
Simple binary trees में insertion fast जाता है।
लेकिन यहाँ split/merge की वजह से operations slow हो सकते हैं।
Worst-case scenario में एक insertion root तक chain reaction split ला सकता है।
7. Real-Time Applications में Deployment मुश्किल
Live production systems (जैसे UPI servers / IRCTC bookings) में कभी-कभी structural changes के कारण performance fluctuation आ जाता है।
इसलिए 2-3 Tree को अकेले rarely deploy किया जाता है; इसे hybrid form में या base concept की तरह इस्तेमाल किया जाता है।
