बैच ऑपरेटिंग सिस्टम (Batch Operating System)
कम्प्यूटर के शुरूआती दिनों में कम्प्यूटर सिस्टम में इनपुट डिवाइस के रूप में कार्ड-रीडर्स (card readers) तथा टेप ड्राइव्स (tape drives) एवम् आउटपुट डिवाइस के रूप में लाइन प्रिंटर्स (line printers), टेप ड्राइव्स (tape drives), तथा पंच कार्ड्स (punch cards) के प्रयोग हुआ करते थे। उस समय यूजर कम्प्यूटर से सीधे-सीधे (directly) इन्ट्रैक्ट न कर, एक जॉब (job) तैयार किया करते थे, जो प्रोग्राम, डेटा और कंट्रोल इनफॉर्मेशन का बना हुआ होता था। यूजर अपने जॉब को तैयार कर कम्प्यूटर ऑपरेटर को सौंप देते थे। जॉब्स, पंच कार्ड्स पर तैयार किए जाते थे। कम्प्यूटर ऑपरेटर सबी जॉब्स को एक साथ लोड कर उन्हें प्रोसेस करता था। कुछ मिनटों, घंटों या दिनों के पश्चात् जॉब्स प्रोसेस होकर आउटपुट देते थे। आउटपुट में प्रोग्राम के परिणाम के साथ-साथ मेमोरी की अंतिम स्थिति की डम्प (dump) तथा रजिस्टर के कनटेन्ट्स (register contents) भी होते थे, जो प्रोग्राम की डिबगिंग (debugging) में सहायक होते थे।
उस समय के ऑपरेटिंग सिस्टम आजकल के ऑपरेटिंग सिस्टम की तुलना में काफी सरल (simple) होते थे। ऑपरेटिंग सिस्टम हमेशा मेमोरी में रेजिडेन्ट (resident) होता था और इसका प्रधान कार्य एक जॉब से दूसरे जॉब पर स्वत: ही कंट्रोल को स्थानान्तरित (transfer) करना था। प्रोसेसिंग स्पीड को बढ़ाने के लिए कम्प्यूटर ऑपरेटर समान प्राथमिकता वाले जॉब्स को एक साथ समूहित (grouped) करके, उन्हें समूह में कम्प्यूटर द्वारा रन करते थे। प्रत्येक जॉब को प्रोसेस करने के पश्चात् उनके आउटपुट सम्बन्धित प्रोग्रामर को दे दिए जाते थे।
ऑपरेटर द्वारा जॉब्स किस प्रकार समूहित किए जाते थे, आइए इसे हम एक उदाहरण से स्पष्ट करते हैं। मान लीजिए ऑपरेटर ने एक FORTRAN का प्रोग्राम, एक COBOL का प्रोग्राम तथा एक अन्य FORTRAN के प्रोग्राम को प्रोसेस करने के लिए इन्हें विभिन्न प्रोग्रामरों से प्राप्त किया। अब यदि ऑपरेटर पहले FORTRAN के प्रोग्राम को, इसके पश्चात् COBOL के प्रोग्राम को और इसके पश्चात् पुन: FORTRAN के प्रोग्राम को रन करें, तो ऐसी परिस्थिति में उसे दो बार FORTRAN कम्पाइलर को टेप (Tape) से लोड करना पड़ता था। परन्तु, यदि ऑपरेटर दोनों FORTRAN प्रोग्राम्स को एक साथ एक बैच (Batch) में रन करे, तो उसे एक ही बार FORTRAN कम्पाइलर को टेप (Tape) से लोड करना पड़ेगा। इस प्रकार ऑपरेटिंग के समय की बचत और जॉब्स की जल्द प्रोसेसिंग होती थी।
समान जॉब्स को एक बैच (batch) के रूप में प्रोसेस करने से, अलग-अलग जॉब को अलग-अलग प्रोसेस करने की तुलना में सिस्टम रिसोर्सेस का अधिक उपयोग सम्भव हुआ। परन्तु एक जॉब से दूसरे जॉब पर ट्रान्जिशन (transition) के समय CPU सुस्त (idle) अवस्था में रहा करता था। दूसरी समस्या यह थी कि जब एक जॉब की प्रोसेसिंग किसी कारणवश रुक (stop) जाती थी, तो उस प्रोग्राम के रुकने के कारणों का पता लगा कर, उसे ठीक कर, उस जॉब को (यदि जॉब कार्ड रीडर से सम्बन्धित हैं) लोड कर, कम्प्यूटर को पुन: स्टार्ट करना पड़ता था।
बैच प्रोसेसिंग में CPU के आइडल टाइम (idle time) को कम करने के लिए रेसिडेन्ट मॉनिटर (Resident Monitor) नामक एक प्रोग्राम क्रिएट किया गया, जो हमेशा मेमोरी में निवास (resident) करता था। रेसिडेन्ट मॉनिटर (Resident Monitor) प्रोग्रामर द्वारा कंट्रोल कार्ड्स (Control Cards) के माध्यम से दिए गए कमाण्ड्स के अनुसार कार्य करता था। कंट्रोल कार्ड्स में जॉब्स के प्रारम्भ (beginnings) और समापन (Endings) के चिन्ह (Marks), प्रोग्राम्स को लोड और एक्जक्यूट करने के कमाण्ड्स, इत्यादि प्रोग्रामर द्वारा जॉब कंट्रोल लैंग्वेज (Job Control Language) में लिखे जाते थे। ये जॉब कंट्रोल लैंग्वेज कमाण्ड्स यूजर के प्रोग्राम और डेटा के साथ उल्लिखित किए जाते थे।
बैच प्रोसेसिंग इन्वायरमेंट (environment) में CPU, अक्सर आइडल (idle) रहता था, क्योंकि इनपुट/आउटपुट डिवाइसेस की गति CPU की गति की तुलना में काफी धीमी होती हैं। उदाहरणस्वरूप, एक CPU, 300 कार्ड्स को प्रति सेकण्ड की गति से एसेम्बल या कम्पाइल कर सकता था, जबकि एक तेज कार्ड रीडर (a first card reader) एक सेकण्ड में केवल 20 कार्ड्स ही रीड कर सकता था। अत: जहां 1200 कार्ड्स को CPU,4 सेकण्डों में एसेम्बल या कम्पाइलर कर सकता था, वहां कार्ड-रीडर को 1200 कार्ड्स को रीड करने में 60 सेकण्डों का समय लगता था। अत: CPU को 60-4=56 सेकण्डों तक आइडल (idle) रहना पड़ा अत: इस उदाहरण के परिप्रेक्ष्य में CPU के टाइम का उपयोग (utilization) केवल 6.7 प्रतिशत हुआ अर्थात् CPU के टाइम के उपयोग का 93.3 प्रतिशत टाइम आइडल (idle) अवस्था में रहा। इसी प्रकार CPU के टाइम की बर्बादी (wastage) आउटपुट ऑपरेशन्स में भी होती हैं।
अत: बैच प्रोसेसिंग में सबसे बड़ी समस्या यह थी कि CPU को तब तक आइडल स्थिति (idle stage) में रहना पड़ता था जब तक कि इनपुट/आउटपुट ऑपरेशन पूरे (complete) न हो जाएं। समय के साथ-साथ टेक्नोलॉजी में विकास हुआ और पहले की तुलना में अधिक तेज गति के इनपुट/आउटपुट डिवाइसेस विकसित हुए। परन्तु इनपुट/आउटपुट डिवाइसेस की गति की तुलना में CPU की गति में कहीं अधिक विकास हुआ। अत: कम्प्यूटर सिस्टम के रिसोर्सेस का अधिकतम उपयोग करने के लिए इनपुट/आउटपुट और प्रोसेसिंग ऑपरेशन्स को एक-दूसरे से ओवरलैप (overlap) करने के लिए चैनल्स (channels), पेरिफेरल कंट्रोलर्स (peripheral controllers) तथा समर्पित इनपुट/आउटपुट प्रोसेसर्स (dedicated input/output processors) का विकास हुआ। इसी दिशा में DMA Chip (Dynamic Memory Access Chip) का भी विकास हुआ जो बिना CPU के हस्तक्षेप (Intervention) के सीधे-सीधे (directly) अपने बफर (Buffer) से डेटा के पूरे ब्लॉक को मेन मेमोरी में स्थानान्तरित (transfer) कर सकता था। जब CPU एक्जक्यूट कर रहा होता हैं, तो DMA इनपुट/आउटपुट डिवाइसेस और मेन मेमोरी के बीच डेटा स्थानातरित (transfer) कर सकता हैं।
कम्प्यूटर सिस्टम के परफॉरमेन्स (performance) को बढ़ाने के लिए, DMA के अलावा बफरिंग (Buffering) और स्पूलिंग (Spooling) नामक दो अन्य एप्रोच भी विकसित किए गए।
बफरिंग (Buffering)
एक मेथड हैं, जिसमें CPU केवल एक और केवल एक ही जॉब (Job) के इनपुट/आउटपुट और प्रोसेसिंग ऑपरेशनों के बीच ओवरलैप (Overlap) करता हैं। बफरिंग (Buffering) में डेटा को इनपुट डिवाइस से रीड करने के पश्चात् CPU इसे प्रोसेस करने लगता हैं तथा प्रोसेसिंग के शुरू होने से ठीक पहले इनपुट डिवाइस अगले इनपुट (data) को रीड करने के लिए ऑपरेटिंग सिस्टम द्वारा निर्देशित (instruct) किया जाता हैं इस प्रकार CPU और इनपुट डिवाइस दोनों ही व्यस्त (busy) रहते हैं। CPU प्रोसेस्ड डेटा (Processed data) को तब तक बफर (buffer) में स्टोर करके रखता हैं, जब तक कि ये डेटा आउटपुट डिवाइस द्वारा स्वीकार (accept) नहीं कर लिए जाते हैं।
स्पूलिंग (Spooling)
साइमलटैनियस पेरिफेरल ऑपरेशन ऑन लाइन (Simultaneous Peripheral Operation On Line) का संक्षिप्त रूप हैं, जो डेटा को रीड तथा आउटपुट को स्टोर करने के लिए डिस्क (disk) का प्रयोग बड़े बफर (Large Buffer) के रूप में करता हैं। स्पूलिंग भी एक मेथड हैं, जिसके द्वारा CPU एक से अधिक जॉब (job) के इनपुट, प्रोसेसिंग और आउटपुट ऑपरेशन्स के बीच ओवरलैप (overlap) करता हैं। अत: स्पूलिंग (Spooling), बफरिंग (Buffering) की अपेक्षा सिस्टम के परफॉरमेन्स (Performance) को कहीं अधिक बेहतर बनाता हैं। स्पूलिंग (Spooling) की प्रक्रिया को कार्यान्वित करने के लिए ऑपरेटिंग सिस्टम, स्पूलर (Spooler) का प्रयोग करता हैं। नीचे दिए गए चित्र में स्पूलिंग (Spooling) को दर्शाया गया है।
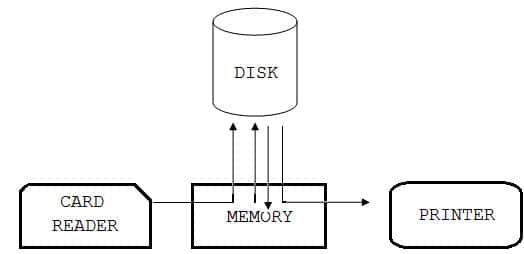
बैच प्रोसेसिंग वैसे प्रोग्राम्स को प्रोसेस करने के लिए उपयुक्त हैं, जिसमें कम्प्यूटेशन (computation) समय अधिक लगता है तथा यूजर के इन्ट्रैक्शन (interaction) की आवश्यकता नहीं होती है। पेरॉल, फोरकास्टिंग तथा स्टैटिसटिकल एनालिसिस ऐसे प्रोग्राम के उदाहरण हैं, जिनमें अधिक कम्प्यूटेशन समय लगता हैं तथा यूजर के इन्ट्रैक्शन (interaction) की आवश्यकता नहीं पड़ती हैं।

