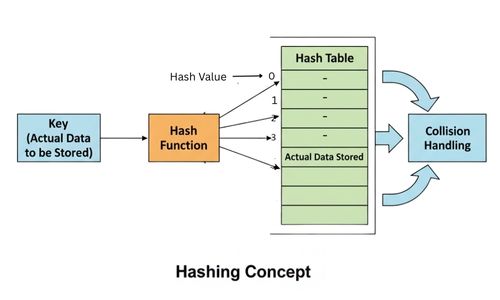
Hashing (Hashing क्या है?)
“Hashing एक Fast data-searching technique है, जिसमें किसी भी data (key) को एक special mathematical formula यानी Hash Function की मदद से एक fixed-size output (hash value या hash code) में बदला जाता है। इससे data को सीधे उसके bucket या slot से O(1) time में जल्दी access किया जा सकता है।”
Table of Contents
ToggleExample :
student का नाम “Ravi Sharma” है।
Hash Function इस नाम को convert करके एक slot number बना देता है, जैसे –
Ravi Sharma → Slot 10
अब जब भी उसका record चाहिए, आप सीधे Slot 10 पर जाकर उसे तुरंत निकाल सकते हैं।
यही Hashing का main idea है — data को जल्दी और efficient तरीके से ढूँढना।
Hash Function (Hash Function क्या होता है?)
“Hash Function एक mathematical function होता है, जो किसी भी input data (key) को process करके एक fixed-size numeric value (hash value / hash code) generate करता है, जिसे hash value या hash code कहते हैं। इस hash value की मदद से उस key को Hash Table में सही slot (index) पर store किया जा सके।”
Formula : Hash(key) = key % table_size
Qualities of a Good Hash Function :
- Uniformity : Hash Function keys को hash table में समान रूप से distribute करता है।
- Deterministic : एक ही input पर हमेशा same hash value देता है।
- Fast Computation : Hash value को बहुत तेजी से calculate करता है।
- Minimum Collisions : अच्छा hash function keys को इस तरह map करता है कि collisions कम से कम हों।
- Full Use of Table Space : Hash values पूरे index range (0 से m–1) में बराबर फैलती हैं, जिससे table का space अच्छी तरह उपयोग होता है।
- Low Clustering : Keys एक ही जगह cluster नहीं होतीं, performance high रहती है।
- Easy to Implement : Function simple, clear और practical होना चाहिए।
Example :
किसी user का mobile number hash करना है –
Hash(9876543210) = 9876543210 % 100 = 10
इसका मतलब है कि यह record slot number 10 में store होगा।
Hash Table (Hash Table क्या होती है?)
Hash Table एक special data structure है, जिसमें data को key-value pair में store किया जाता है, और keys को hash function के द्वारा एक specific index में map करके बहुत fast searching, insertion और deletion किया जाता है।
Example :
- Index 0 → empty
- Index 1 → empty
- Index 2 → Amir
- Index 3 → empty
- Index 4 → Neha
Hash Collision (Hash Collision क्या होती है?)
जब दो अलग-अलग keys को hash function एक ही index पर map कर देता है, तो इस स्थिति को Hash Collision कहा जाता है।
Example :
h(key) = (first letter ASCII) % 5
- Amit → Index 0
- Anu → Index 0
Applications of Hashing (अनुप्रयोग)
- Password Storage : Facebook, Instagram, IRCTC जैसे platforms users के passwords को hash करके store करते हैं।
- Database Indexing : Large SQL databases में fast search के लिए hash index use होता है।
- Caching Systems : YouTube, Netflix, Amazon Prime — fast content delivery hashing पर depend करती है।
- Blockchain : Bitcoin और Ethereum में Hashing fundamental element है।
- File Integrity Check : Software download करते समय SHA-256 hash verify किया जाता है।
- Compiler Symbol Table : C, Java compilers variables को hash करके store करते हैं।
Advantages of Hashing (लाभ)
1. Very Fast Searching
- Search time लगभग हमेशा O(1) रहता है, क्योंकि data को direct उसके index से access किया जाता है।
2. Efficient Insertion & Deletion
- Data को add या delete करते समय array shifting की ज़रूरत नहीं पड़ती, इसलिए operations बहुत fast होते हैं।
3. Large Data Handling
- Hash Table बड़े datasets को भी आसानी से handle कर लेती है, और performance high रहता है।
4. No Need to Sort Data
- Hashing में data को sorted रखने की requirement नहीं होती।
5. Uniform Data Distribution
- एक अच्छा hash function keys को पूरे table में evenly distribute करता है, जिससे collisions कम होती हैं।
6. Used in Many Applications
- Password storage, database indexing, caches, compilers, blockchain जैसी कई technologies में hashing का use होता है।
Disadvantages of Hashing (सीमाएं)
1. Hash Collision Problem
- कभी-कभी दो keys का same index बन जाता है—इसे handle करने के लिए extra techniques की ज़रूरत होती है।
2. Not Good for Range Queries
- { BETWEEN, < , > } जैसे range-based searches hashing में सीधे possible नहीं होते, क्योंकि data sorted नहीं होता।
3. Space Overhead
- Large hash tables में कई empty buckets रह सकते हैं, जिससे memory waste होती है।
4. Performance Depends on Hash Function
- अगर hash function खराब हो, तो collisions बढ़ जाती हैं, और overall performance slow हो जाता है।
5. Deletion Handling Complex
- Collision methods (जैसे chaining या open addressing) होने पर deletion थोड़ा complicated हो सकता है।
6. Security Risk (Weak Hash Functions)
- Weak hash functions का use करने पर password cracking या collision attacks का खतरा बढ़ जाता है।
Indexing
Indexing एक database technique है, जिसमें search speed fast करने के लिए special data structures बनाए जाते हैं, जिन्हें Index कहते हैं।
Example :
मान लीजिए आपके पास 5 books के नाम की list है –
- History of India
- Chemistry Basics
- Maths Formulas
- Biology Notes
- Physics Concepts
अगर आपके पास index नहीं है, तो ‘Maths Formulas’ ढूँढने के लिए पूरी list पढ़नी पड़ेगी। लेकिन अगर आपने alphabet-based index बना लिया, तो search करना बहुत आसान हो जाता है –
- B → Biology Notes
- C → Chemistry Basics
- H → History of India
- M → Maths Formulas
- P → Physics Concepts
अब जैसे ही आप ‘M’ पर जाते हैं, सीधे Maths Formulas तक पहुँच जाते हैं।
यही Indexing है — search को fast और direct बनाना।
Why Indexing is Used? (Indexing क्यों उपयोग होती है?)
- Fast Searching : Index की मदद से database records को बहुत जल्दी locate कर लेता है।
- Query Performance Improved : SELECT queries, especially WHERE clauses, indexing से तेज़ हो जाती हैं।
- Full Table Scans Avoided : System को पूरा table line-by-line नहीं पढ़ना पड़ता।
- Large Database Handling Easy : Millions records वाले tables में भी data instant मिलता है।
- Sorting Operations Are Faster : Indexed columns internally sorted होते हैं, जिससे ORDER BY/ GROUP BY तेज चलते हैं।
- Joins Are Faster : Multi-table joins में indexed columns match जल्दी होते हैं।
- Better User Experience : Flipkart, Amazon, IRCTC में fast searching इसी वजह से possible है।
Types of Indexing (Indexing के प्रकार)
1. Primary Index
- यह primary key पर बनाया जाता है।
- हर record के लिए unique entry होती है।
- Table के rows पहले से sorted order में होते हैं।
- Fast और सबसे reliable indexing methods में से एक।
Example : Student table में Roll Number (Primary Key) पर Index।
2. Secondary Index
- यह non-primary key या किसी भी normal column पर बनाया जाता है।
- Table sorted नहीं भी हो तब भी बनाया जा सकता है।
- Multiple secondary indexes possible हैं।
Example : Name, City, या Email column पर index बनाना।
3. Clustered Index
- Data physically उसी order में store होता है जैसा Index order बताता है।
- एक table में केवल एक clustered index हो सकता है।
- Searching बहुत fast होती है क्योंकि data sorted रहता है।
Example : SQL Server में Primary Key automatically clustered index बन जाता है।
4. Non-Clustered Index
- Data की physical arrangement change नहीं होती।
- Index अलग से pointer structure बनाता है।
- एक table में कई non-clustered indexes हो सकते हैं।
Example : Employee table में Salary या Department पर indexing।
Advantages of Indexing (लाभ)
1. Fast Searching
- Indexed columns पर search बहुत तेज़ होती है, क्योंकि full table scan की जरूरत नहीं पड़ती।
2. Query Performance Improve
- SELECT queries, खासकर WHERE, ORDER BY, GROUP BY, जल्दी execute होती हैं।
3. Efficient for Large Databases
- Millions of records वाले tables में भी result बहुत जल्दी मिलता है।
4. Supports Range Queries
- { LIKE, BETWEEN, >, < } जैसे range-based queries efficiently perform होती हैं।
5. Better Disk I/O Performance
- कम blocks read होते हैं, जिससे overall performance बढ़ती है।
6. Faster Joins
- Indexed columns के साथ multi-table joins जल्दी match होते हैं।
7. Sorted Data Access
- Clustered indexing में data पहले से sorted रहता है, इसलिए sorted queries fast होती हैं।
Disadvantages of Indexing (सीमाएं)
1. Extra Storage Space
- Index के लिए additional memory या disk space की जरूरत होती है।
2. Slower Insert/Update/Delete
- Table में record add, update या delete करते समय index को भी update करना पड़ता है, जिससे extra time लगता है।
3. Maintenance Overhead
- Frequent updates और inserts वाले tables में indexes maintain करना costly हो सकता है।
4. Not Always Necessary
- Small tables या rarely queried tables में indexing की जरूरत नहीं होती।
5. Complexity Increase
- Multi-level या multi-column indexes system को थोड़ा complex बना सकते हैं।


