
एमएस एक्सेस 2013 में Normalization क्या हैं?
(Normalization in MS Access 2013)
Normalization क्या हैं ? (What is Normalization?)
Normalization डेटाबेस डिज़ाइन को सरल बनाता है इसे डेटाबेस Normalization या डेटा Normalization के रूप में भी जाना जाता है, Normalization डेटाबेस डिज़ाइन का एक महत्वपूर्ण हिस्सा है, क्योंकि यह डेटाबेस की गति, सटीकता में सहायता करता है। Normalization एक ऐसी तकनीक है जिसका उपयोग relational डेटाबेस को डिजाईन करने के लिए किया जाता है। Normalization दो प्रक्रिया में होती है जो डाटा से Repeating Groups को हटा कर टेबल के रूप में रखती है और उसके बाद रिलेशनल टेबल से एक जैसी यानी कि duplicate entries को remove करती है|
Normalization का काम redundancy को कम करना होता है और redundancy को कम करने का अर्थ हैं एक information को एक ही बार स्टोर करना। एक ही Information को एक से ज्यादा बार स्टोर करने से स्टोरेज बढता है। रिलेशनल Normalized से मतलब है कि जब भी डेटाबेस में रिलेशन्स को alter किया जाए, तो इनफार्मेशन गुम नही होना चाहिए।
डेटाबेस को Normalization करके, आप डेटा को टेबल और कॉलम में व्यवस्थित कर सकते हैं। आप सुनिश्चित करते हैं कि प्रत्येक टेबल में केवल संबंधित डेटा होता है। यदि डेटा सीधे संबंधित नहीं है, तो आप उस डेटा के लिए एक नई टेबल बनाते हैं।
उदाहरण के लिए, यदि आपके पास “ग्राहक” टेबल है, तो आप आमतौर पर उन उत्पादों के लिए एक अलग टेबल बना सकते हैं, जिन्हें वे ऑर्डर कर सकते हैं (आप इस टेबल को “Product” कह सकते हैं)। आप ग्राहकों के आदेशों के लिए एक और टेबल तैयार करेंगे (शायद “ऑर्डर” कहा जाता है)। और यदि प्रत्येक ऑर्डर में कई आइटम हो सकते हैं, तो आप आमतौर पर प्रत्येक ऑर्डर आइटम को स्टोर करने के लिए एक और टेबल बनाते हैं (शायद “ऑर्डरइटम” कहा जाता है)। इन सभी टेबलओं को उनकी प्राथमिक कुंजी से जोड़ा जाएगा, जो आपको इन सभी टेबलओं (जैसे किसी दिए गए ग्राहक द्वारा सभी ऑर्डर) में संबंधित डेटा ढूंढने की अनुमति देता है।
Normalization के लाभ (Benefits of Normalization)
- यह डेटा रिडंडेंसी को कम करता है (डुप्लिकेट डेटा)।
- यह शून्य मूल्यों (null values) को कम करता है।
- यह अधिक कॉम्पैक्ट डेटाबेस में परिणाम देता हैं| (कम डेटा रिडंडेंसी / शून्य मानों के कारण)।
- यह डेटा संशोधन मुद्दों को कम करता हैं|
- यह क्वेरी को सरल बनाता है।
- यह डेटाबेस संरचना को स्वच्छ और समझने में आसान बनता है।
- आप मौजूदा डेटा को जरूरी रूप से प्रभावित किए बिना डेटाबेस का विस्तार कर सकते हैं।
- इसमें इंडेक्स खोजना, सॉर्ट करना और बनाना तेजी से हो सकता है, क्योंकि टेबल संकुचित होते हैं, और डेटा पंक्ति पर अधिक पंक्तियां फिट होती हैं।
एक Normalization डेटाबेस का उदाहरण (Example of a Normalized Database)
एक रिलेशनल डेटाबेस डिज़ाइन करते समय, आमतौर पर एक स्कीमा बनाने से पहले डेटा को Normalization करता है। डेटाबेस स्कीमा संगठन और डेटाबेस की संरचना को निर्धारित करता है – मूल रूप से डेटा कैसे संग्रहीत किया जाएगा।
Normalization डेटाबेस स्कीमा का एक उदाहरण यहां दिया गया है:
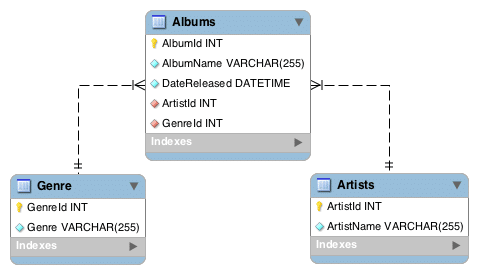
यह स्कीमा डेटा को तीन अलग-अलग टेबलों में विभाजित करता है। प्रत्येक टेबल उस डेटा में काफी विशिष्ट है जो इसे स्टोर करती है – एल्बमों के लिए एक टेबल है, कलाकारों के लिए एक है, और दूसरा जो डेटा के लिए विशिष्ट डेटा रखता है। हालांकि, रिलेशनशिप मॉडल हमें इन टेबलों के बीच रिलेशन बनाने की इजाजत देता है, हम यह पता लगा सकते हैं कि कौन से एल्बम किस कलाकार से संबंधित हैं, और किस शैली में वे संबंधित हैं।
Normalization के प्रकार (Types of Normalization)
1. First normal form(1NF):-
First Normal Form को 1NF से भी दर्शाते हैं, एक relational table 1NF में होती है जब column की सभी values Atomic होती है। यानी कि उसमें repeating values नही होती है। हम इसे इस तरह से भी समझ सकते है कि कोई table 1 NF में होती है यदि-
- Table में कोई Duplicate Row नही होनी चाहिए।
- हर एक Cell में single Values होनी चाहिए।
- Column में entries का प्रकार एक जैसा ही होना चाहिए।
2. Second normal form(2NF):-
एक टेबल या रिलेशन तब 2nd normal form में होता है जब वह 1st normal form की सभी जरूरतों को पूरी करता हों और सभी non key attributes पूरी तरह से primary key पर निर्भर हों।
3. Third normal form(3NF):-
कोई टेबल या रिलेशन तब 3rd normal form में होता है जब वह 2nd normal form की सभी जरूरतों को पूरी करता हो तथा उनमें transitive function dependency नही होनी चाहिए।



